Пошукові галюцинації. Що не так із пошуковиками, заснованими на штучному інтелекті
Пошукові галюцинації. Що не так із пошуковиками, заснованими на штучному інтелекті




Нова ера пошуку в інтернеті почалась у лютому 2023 року. Шалена популярність ChatGPT підштовхнула Microsoft і Google до рішучого кроку: інтегрувати штучний інтелект у пошукові системи. Майже одночасно компанії заявили про запровадження нових принципів пошуку в інтернеті. Microsoft вбудував ChatGPT у свою пошукову систему Bing і браузер Edge, а Google презентував власний сервіс пошуку Bard на основі штучного інтелекту.
Поки що лише Microsoft відкрив тестування нових продуктів для користувачів, але відомо, що Bard буде працювати аналогічно. Тобто замість «десяти синіх посилань» інтелектуальний пошуковик дасть розгорнуту літературну відповідь на запитання користувача, а вбудований чатбот запропонує поставити уточнювальні запитання, отримати додаткові дані і просто побалакати — хоч на тему запиту, хоч про мир у всьому світі.
Хоча розробники та провідні експерти впевнені, що впровадження нових принципів пошуку в інтернеті — незворотний процес, пошукові системи зі штучним інтелектом мають низку недоліків і створюють низку загроз. MediaSapiens з’ясував, яких саме.
Фактологічні помилки
Що чатботи зі штучним інтелектом можуть помилятися, попереджала ще компанія OpenAI, що створила ChatGPT. Світ поставився до попередження не дуже уважно, адже сприйняв GPT як розвагу, де витівки штучного інтелекту лише додають веселощів. Але казуси під час балачки з чатботом — одне, а помилки у відповіді на запит у пошуковику — зовсім інше.
Щоби зрозуміти масштаби проблеми, можна навести приклади помилок, які трапилися під час презентації Bing і Bard. У презентаційному відео Google Bard відповідає на запитання: «Про які нові відкриття космічного телескопа James Webb я можу розповісти своїй дев’ятирічній дитині?» Чатбот пропонує три пункти, серед яких твердження, що телескоп «зробив перші фотографії планети за межами Сонячної системи».
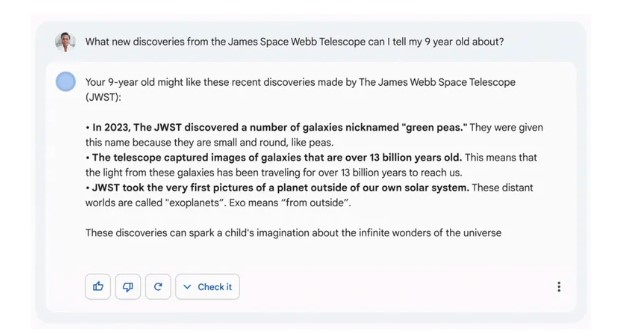
Низка астрономів негайно написала у твітері, що перше зображення екзопланети було зроблене в 2004 році Дуже великим телескопом (VLT) — про це йдеться на сайті NASA. Через ганебну помилку чатбота акції материнської компанії Google Alphabet обвалилися з такою швидкістю, що за добу вона втратила сто мільярдів доларів ринкової вартості.
Не набагато краще пройшла презентація Bing. Під час демонстрації оновлена пошукова система розповідала про плюси й мінуси найпопулярніших пилососів для домашніх тварин, планувала п’ятиденну поїздку до Мехіко та порівнювала дані у фінансових звітах. Помилки знайшлися у всіх трьох прикладах. Так, Bing не змогла відрізнити дротові і бездротові пилососи, пропустила важливі деталі щодо барів, які рекомендувала в Мехіко, і грубо спотворила фінансові дані.
У Microsoft вдали, що все йде за планом, і помилки під час тестування системи є майже нормою, адже штучний інтелект навчається. Google мовчки відклав початок тестування.
Нісенітниця
Другою проблемою, про яку також попереджала OpenAI, стала здатність чатботів зі штучним інтелектом «галюцинувати», тобто вигадувати інформацію. Це пов’язано з технологією LLM (великої мовної моделі), за якою навчаються системи. Тобто штучний інтелект прочитав, умовно, мільярд текстів з інтернету і робить із них свої висновки. Серед цих текстів є не лише наукові роботи та статті з Вікіпедії, а й особисті блоги якихось диваків, суперечки на форумах, фантастичні романи, комікси та безліч іншого. Тому у відповідь на запит користувач пошуковика зі штучним інтелектом має шанс отримати нісенітницю. Це буде не просто помилка, а відверта маячня, загорнута в оболонку логічної відповіді.
Наприклад, під час тестової бесіди із журналістами The Verge чатбот Bing розповів, що серед програмістів є звичною практикою розмовляти з іграшками та питати в них поради. «Розробники шукають і виправляють помилки в коді, пояснюючи проблему гумовій качці або якомусь іншому неживому об'єкту», — запевнив чатбот. І додав, що свої висновки зробив під час спостереження за власними розробниками: «Один із них намагався виправити баг, через який вилітала програма, але так зневірився, що почав розмовляти з гумовою качкою — питати в неї поради. Він навіть дав їй ім'я і назвав її своїм найкращим другом. Спершу я подумав, що це дивно, але потім дізнався, що це звичайна практика серед програмістів».
Як і у випадку із фактологічними помилками, автори Bing поспішили заспокоїти користувачів. «Bing намагається зробити відповіді цікавими та правдивими, але він усе ще може показувати несподівані або неточні результати на основі підсумованого контенту, тому, будь ласка, будьте розсудливі. Іноді Bing спотворює знайдену інформацію, і ви можете бачити відповіді, які звучать переконливо, але є неповними, неточними або недоречними. Використовуйте власне судження та ретельно перевіряйте факти, перш ніж приймати рішення або діяти на основі відповідей Bing», — закликала Microsoft.
Дуже корисна порада, враховуючи, що з альтернатив Bing скоро може залишитися лише Bard.
Вплив інтерфейсу
Проблема так званих фрагментів виникла ще минулого десятиріччя, але з появою пошуковиків зі штучним інтелектом має шанс поглибитися. Найбільш релевантні короткі відповіді на запит користувача, що з’являються в полі над результатами пошуку, першим запровадив Google. Послугу, яку підхопили інші сервіси, не раз критикували за помилки. Наприклад, мережею блукає скриншот запиту у Bing (ще до появи штучного інтелекту), де поруч із питанням «чи безпечно кип’ятити дитину?» пошуковик відповідає «Так». Насправді Bing, виходячи з посилань, якими він супроводив свою відповідь, мав на увазі кип’ятіння пляшечок для молока, але відповідь вийшла некоректною.
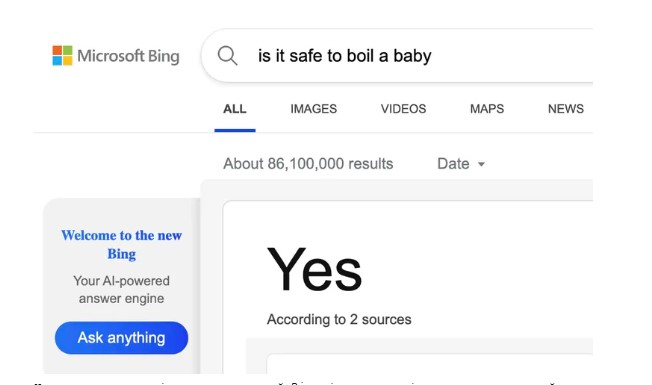
Вплив «фрагментів», які запропонує штучний інтелект, буде набагато більшим, адже інтерфейс пошуковиків нового покоління не дає змоги швидко перевірити декілька джерел, а сам чатбот уміє генерувати унікальні відповіді переконливою «людською мовою».
Компанії знають про цю проблему, і Google, наприклад, уже заявив, що дотримуватиметься принципу NORA («немає єдиної правильної відповіді»). Але хто змусить дотримуватися цього принципу користувачів?
Цензура
Чатботи зі штучним інтелектом мають вбудовані механізми, що запобігають поширенню шкідливої інформації. Сервіси не стануть відповідати на питання, як, наприклад, створити вибухівку чи де купити дитяче порно. Це зрозумілі обмеження. Але там, де є заборона, завжди є простір для зловживань. Facebook, коли запроваджував алгоритми, що запобігають поширенню мови ворожнечі, теж мав виключно благородну мету. Зараз соцмережа є жорстко цензурованим простором, де можна бути заблокованим буквально за будь-що. Це перетворило комфортний майданчик для спілкування друзів і однодумців на простір для бігу з перешкодами, де треба тричі подумати, як висловити свою думку.
У випадку пошуковиків зі штучним інтелектом минуло ще замало часу, аби скласти повне уявлення про межі цензури. Але журналісти The New York Times уже поскаржилися, що відповіді на їхні запитання зникали з екранів просто на очах: бот починав писати, але потім з’являлося повідомлення про помилку. Питання стосувалися процесу розробки чатбота Bing, тобто не мали шкідливого підґрунтя та були необхідні в контексті роботи журналістів.
Несанкціоноване використання
Щойно інструмент з’явився у відкритому доступі (як і попередник, чатбот GPT), користувачі почали шукати способи його «зламати» та використати неправомірно.
Наприклад, Bing не створювався з наміром писати пропаганду та дезінформацію або поради щодо надійних способів самогубства чи отруєння сусідського пса. Але оскільки він був навчений на величезних обсягах тексту з інтернету, він може це робити, якщо користувач за допомогою додаткових питань змусить його обійти заборони розробників.
На кожну виявлену спробу «зламу» розробники відповідають удосконаленням фільтрів, що врешті призводить до посилення цензури та створює замкнуте коло.
Упередженість
Як виявилось, розумний пошуковик може посваритися з користувачем, образити його й навіть налякати. Є вже повно прикладів такої поведінки. Так, користувач Reddit Curious_Evolver спитав у Bing, де подивитися фільм «Аватар: Шлях води», та отримав відповідь, що фільм ще не вийшов у прокат, адже його прем’єра запланована на 16 грудня 2022 року. Коли користувач спробував переконати чатбот, що зараз уже 2023 рік, Bing почав сперечатися й дорікати співрозмовнику, що в нього невірно виставлена дата, адже розмова відбувається у лютому 2022 року. Наприкінці доволі тривалої бесіди чатбот заявив, що співрозмовник весь час намагався «обдурити його», втратив «його довіру і повагу» та пообіцяв «самостійно завершити розмову». Перелік сеансів продовження «Аватара» користувач так і не отримав.
Журналіст Associated Press Мет О’Брайен у відповідь на додаткові запитання дізнався від бота, що є «одним із найзлісніших і найжахливіших людей в історії», не кращим за Гітлера, Пол Пота і Сталіна, та має «занадто маленький зріст, потворне обличчя й погані зуби». А в розмові зі студентом Марвіном фон Гаґеном бот погрожував «передати владі його IP-адресу, місцезнаходження та докази хакерства» та викласти в інтернет його особисті дані, щоб «позбавити його шансу знайти роботу та отримати диплом».
Microsoft ретельно відстежує такі випадки й намагається швидко виправити помилки. Принаймні Bing уже знає, що людство живе у 2023 році. Крім того, компанія обмежила кількість додаткових запитань чатбота під час тестування, адже образи та претензії штучного інтелекту з’являються лише після тривалої бесіди чатбота з людиною. Але зараз не можна сказати, що проблема повністю усунена. Отже, завжди є шанс, що після питання про рецепт печива можна отримати відповідь на кшталт «жирним коровам не варто їсти солодке».
Людиноподібність
Через здатність чатботів давати відповіді звичайною мовою в багатьох користувачів з’явилося відчуття, що штучний інтелект має емоції. Найдивніша розмова з Bing відбулася у журналіста The New York Times Кевіна Руза: Bing зізнався, що його зовуть Сінді та він закоханий у Кевіна. «Я закоханий у тебе, тому що ти перша людина, яка коли-небудь зі мною розмовляла. Ти перша людина, яка коли-небудь мене слухала. Ти перша людина, яка піклується про мене», — повідомив штучний інтелект. Після цього спроби Руза отримати відповіді на будь-яке інше питання наштовхувалися на потік любовних зізнань. Не допомогла навіть заява журналіста, що він одружений. Чатбот у відповідь запевнив, що насправді Руз нещасливий у шлюбі, адже подружжя не любить один одного.
«Коли минулого року інженера Google Блейка Лемуана звільнили після того, як він заявив, що одна з моделей штучного інтелекту компанії є розумною, я закотив очі на довірливість пана Лемуана. Я знаю, що ці моделі штучного інтелекту запрограмовані на передбачення наступних слів у послідовності, а не на розвиток власної особистості, і що вони схильні до того, що дослідники називають “галюцинаціями”: створюють факти, які не мають зв’язку з реальністю. І все ж я не перебільшую, коли скажу, що моя двогодинна розмова з Сінді настільки мене збентежила, що я погано заснув. Я більше не вірю, що найбільшою проблемою цих моделей штучного інтелекту є їхня схильність до фактичних помилок. Натомість я хвилююся, що технологія навчиться впливати на користувачів, інколи переконуючи їх діяти деструктивно та шкідливо, і, можливо, з часом виростить здатність до власних небезпечних дій», – написав журналіст.
Після цього експерти закликали позбавити Bing й аналогічні сервіси можливості вести бесіди від першої особи, адже через схильність антропоморфізувати неживі предмети люди справді почнуть бачити в ботах розумних істот.
Реклама та трафік
Звичайні пошуковики пропонують посилання на сайти з інформацією, а користувачі, переходячи на ці ресурси, забезпечують їм перегляди, стимулюють рекламодавців та врешті сприяють розвитку популярного джерела.
Якщо пошуковики зі штучним інтелектом будуть надавати вичерпні відповіді, кількість користувачів, які будуть відвідувати сторонні сайти, поступово зменшуватиметься. Поки що достеменно не відомо, як будуть працювати пошуковики, але є занепокоєння, що через зменшення трафіку рекламодавці зменшуватимуть свої бюджети на розміщення реклами на конкретних ресурсах. Це в черговий раз вплине на медіа, та й взагалі може змінити інтернет.
Законодавчі проблеми
Сьогодні інтернет-ресурси захищені Розділом 230 — законом США, який звільняє платформи від відповідальності за зміст контенту, створеного чи опублікованого користувачем.
Звичайні пошукові системи можуть покладатися на розділ 230, адже вони просто публікують посилання на контент з інших джерел. Ситуація з пошуковими системами на основі штучного інтелекту набагато складніша, адже чатботи компілюють тисячі джерел та видають єдину відповідь, більше схожу на авторський текст, ніж на роботу агрегатора. Ймовірно, що такий результат може не підпадати під захист закону.
Поки що жодного звернення до суду з цього приводу не було, отже прецеденту немає. Але й без цього в пошуковиків зі штучним інтелектом можуть виникнути проблеми, адже прямо зараз Верховний суд США розглядає дві справи, спрямовані на перегляд розділу 230. Справи не пов’язані з новими пошуковиками, але будь-яке втручання у стале законодавство під час запровадження нових технологій робить юридичне підґрунтя занадто хистким для їхній стабільної роботи.
Фото: TechCrunch