

Meta презентувала модель ШІ, яка розпізнає понад 4 тисячі мов
Виділіть її та натисніть Ctrl + Enter —
ми виправимo
Meta презентувала модель ШІ, яка розпізнає понад 4 тисячі мов




Meta створила мовну модель штучного інтелекту Massively Multilingual Speech (MMS), яка здатна розпізнавати понад 4 тисячі мов і синтезувати текст у мовлення понад 1100 мовами. Про це компанія повідомила у своєму блозі.
«Сьогодні ми публічно ділимося нашими моделями та кодом, щоб інші в дослідницькому співтоваристві могли використовувати нашу роботу, — зазначено в повідомленні. — Завдяки цій роботі ми сподіваємося зробити невеликий внесок у збереження неймовірного мовного розмаїття світу».
Створення і подальший розвиток MMS передбачає уможливити доступ до інформації та використання пристроїв тією мовою, якою володіє користувач: від технологій віртуальної та доповненої реальності до служб обміну повідомленнями.
«Моделі MMS розширюють технологію перетворення тексту в мовлення та мовлення в текст із приблизно 100 мов до понад 1100 — у понад 10 разів більше, ніж раніше», — зазначили в компанії.
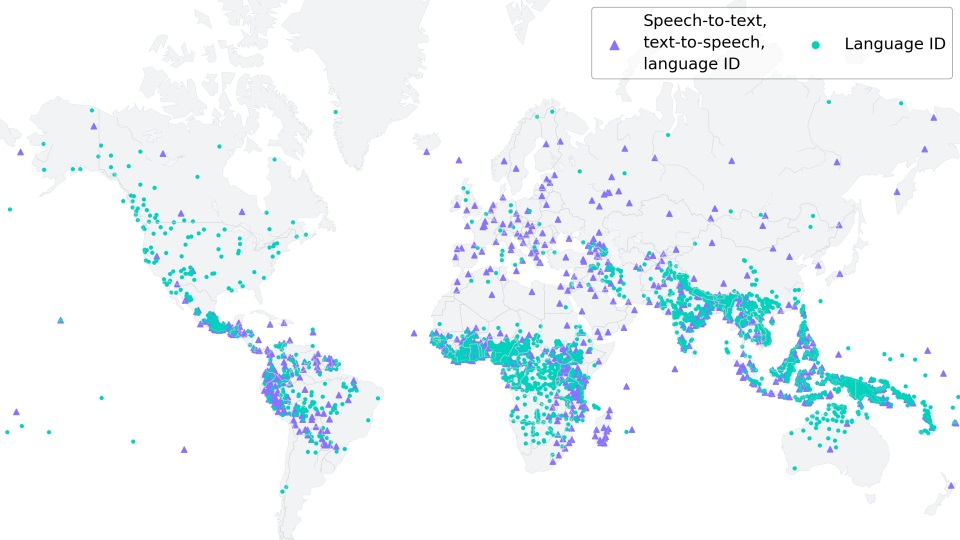
Для навчання MMS розпізнавання мов вдалися до нестандартного підходу — звернулися до релігійних текстів. Біблія та інші основні книги світових релігії перекладені великою кількістю мов, і існує безліч загальнодоступних аудіозаписів, де ці тексти зачитуються. Навчання моделі ускладнилося через те, що аудіозаписи не мали точної текстової розмітки, але в підсумку кількість мов, що підтримуються, перевищила 4 тисячі.
«Хоча ці тексти часто начитуються представниками чоловічої статі, аналіз показав, що наші моделі однаково добре працюють як для чоловічого, так і для жіночого голосу, — зазначили в Meta. — І хоча зміст аудіозаписів є релігійним, аналіз показав, що це не спонукає модель створювати більш релігійне мовлення».
У компанії додали, що збираються розширювати перелік мов, якими володітиме MMS. Очікується, що в подальшому вона опанує і регіональні діалекти.
Нагадаємо, в лютому CEO компанії Meta Марк Цукерберг оголосив про намір розробити чатботи зі штучним інтелектом для Messenger, Instagram і WhatsApp.
Тим часом український стартап Respecheecher почав тренувати безкоштовну нейромережу для розпізнавання кримськотатарської мови. Для цього команда збирає 1000 голосів кримців.
Фото: Pexels











