Чотири рецепти дослідження фейків за допомогою онлайн-інструментів
Чотири рецепти дослідження фейків за допомогою онлайн-інструментів




Дослідники з мережі Public Data Lab за підтримки First Draft розробили своєрідне польове керівництво з фейків та «інформаційних розладів». У ньому вони підкреслюють, що фейки варто розглядати не як окреме явище, а в контексті того, як вони циркулюють в онлайні.
Саме до цього автори й намагаються спонукати своїх читачів: відійти від формального розуміння штучних новин до загального розуміння того, як вони поширюються в інтернеті.
«У посібнику ми пропонуємо нові способи відображення та реагування на фейкові новини, крім їх виявлення та фактчекінгу — у тому числі більш точний аналіз того, як вони циркулюють та мобілізують людей», — пояснюють автори у вступі.
Що пропонують автори? Збірку «рецептів» — зовсім як у кулінарній книзі. З тією лише різницею, що їхні рецепти дають керівництво з аналізу фейків, а не приготування страв.
«Ми ілюструємо низку методів і процедур, які читачі можуть використовувати для того, щоб самостійно вивчати феномен фейкових новин», — пояснюється в керівництві. Вони також заохочують читачів не лише сліпо повторювати запропоновані «рецепти», але вдосконалювати й виходити за їх рамки.
Дослідники також вказують, що поширення фейкових новин залучає більше сторін, аніж кілька а́кторів-поширювачів чи державну змову — і, на їхню думку, це зачіпає важливі та складні питання про роль цифрових технологій у суспільстві і про те, як ми взаємно формуємо їх.
«Рецепт 1». Визначаємо, які типи аудиторії залучають фейкові новини на Facebook
Циркулювання несправжніх чи оманливих тверджень не одразу стає «поширенням фейкових новин». Для цього їм спершу потрібно залучити велику кількість публіки, включно з прихильниками, «лайками» та поширеннями, а також опонентами, які будуть виявляти їх та спростовувати.
Архітектура Facebook ускладнює вивчення циркуляції таких новин через систему доступів та дозволів. Тому дослідники пропонують зосередитися на відстежуванні аудиторії фейкових новин, аналізуючи сторінки та групи в соцмережі.
У цьому рецепті чотири кроки:
- ідентифікувати теми, які експлуатуються в потоці фейків,
- визначити, які відомі публічні сторінки та групи у Facebook поширювали ці історії,
- розглянути, чи є в цієї аудиторії улюблені теми, до яких вона звертається частіше,
- підсумувати зібрану інформацію та скласти збірний образ аудиторії, яка охоче приймає та поширює фейки.
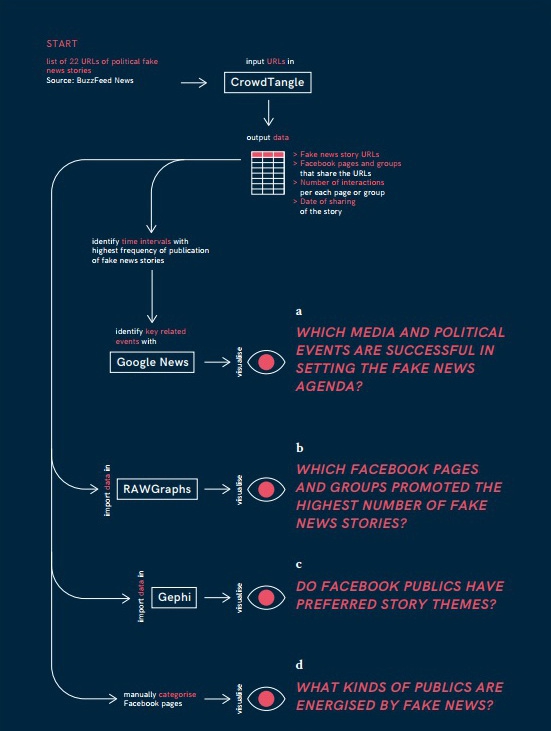
Для першого кроку варто зосередитися на окремій політичній події та часовому проміжку, які будуть встановлювати рамки для аналізу. Наприклад, у керівництві — це поширення фейків напередодні президентських виборів у США в 2016 році.
Автори радять користуватися сервісом WayBack Machine, якщо деякі з фейків більше недоступні в онлайні, але могли зберегтися в цьому архіваторі. Агрегатор Google News Search допоможе в пошуку тем та новин, які були актуальними в той проміжок часу, який вас цікавить. Як відправну точку для пошуку зв'язків між політичними та медійними подіями й поширенням фейків у керівництві радять використовувати графічний таймлайн.
Дослідники використали для прикладу 22 лінки на фейкові статті. Вони проаналізували їх за допомогою розширення для браузера CrowdTangle — цей інструмент дозволяє відстежувати, як контент поширюється в мережі та наскільки ефективно він залучав аудиторію на Facebook, Twitter, YouTube, Instagram та Vine. Потім вони виокремили на таймлайні той проміжок, коли фейки публікувалися з найменшим інтервалом часу. Після цього вони почали шукати ключові релевантні події — проаналізувавши новини за допомогою Google News Search, які були актуальними в той же час.

Приклад таймлайну, створеного на основі аналізу даних із CrowdTangle та Google News Search. Він виявив, що фейкові новини перед виборами 2016 року найчастіше використовували теми націоналізму, антиімміграційні настрої. Вони також експлуатували негативні риси кандидатів на пост президента — такі як корумпованість та мізогонію.
Для створення візуалізацій на основі зібраних даних можна використати сервіс RAWGraphs. Він дозволяє генерувати коди вставки, які потім можна поширювати чи вбудовувати на сайті.
Через CrowdTangle можна аналізувати не лише контент, який поширювався в соцмережах, але й сторінки, які його поширювали. Ще один сайт, який може стати в нагоді при аналізі, — Gephi. Він допомагає знаходити спільні схеми і тренди у зібраних даних та потім візуалізувати їх. В одному з наступних рецептів ми ще повернемося до нього.

Популярні теми серед публічних сторінок на Facebook. Синіми колами позначено URL фейкових історій. Червоними — сторінка чи група, які з ними взаємодіяли. Чим інтенсивніший колір — тим активнішою була взаємодія між цими компонентами.
За допомогою CrowdTangle можна знайти сторінки та групи, які активно поширювали фейки за обраний для аналізу період. Тепер можна придивитися й до їхньої аудиторії — на жаль, автоматизованого інструменту для цього автори не пропонують. Але прискорити процес можна за допомогою описів, які вказують самі сторінки — наприклад, в окрему категорію приплюсовувати аудиторію сторінок із бізнес-тематики, активістів, тих, хто стежить за сторінками публічних людей, і так далі. Так можна поділити аудиторію фейкових сторінок на умовні категорії й виявити найбільші. Цей «рецепт» може стати в нагоді зацікавленим в аналізі того, хто й навіщо активізує поширення фейків у певний проміжок часу.
«Рецепт 2». Відстежуємо траєкторію поширення фейкових новин на Facebook?
У цьому рецепті дослідники виділили два аспекти:
- відстежування окремої сторінки, яка поширила лінк на статтю чи новину,
- відстежування всіх сторінок, які поширили певний лінк.
Для цього знову знадобиться розширення браузера CrowdTangle. У прикладі дослідники аналізували новину, згідно з якою гурт Rage Against the Machine відроджується й планує випустити антитрампівський альбом.
Для обробки усіх результатів радять знову звернутися до таймлайну, який можна створити в RAWGraphs. Дослідники змогли відстежити новину в своєму прикладі до липня 2016 року — вона з’явилася на сторінці Rock Feed і була підхоплена іншими англомовними сторінками. Після цього новину почали цитувати й іноземні сторінки.
У другому прикладі дослідники шукали, як у соцмережі Facebook розійшлася новина про те, що Дональд Трамп обіцяє безкоштовні квитки до Африки та Мексики усім, хто бажає виїхати зі США. Із цією метою вони використали Google Web Search, за допомогою якого можна переглянути результати пошуку відповідно до ранжування сторінок. Так, ті сторінки, з якими аудиторія найбільше взаємодіяла й найактивніше поширювала, будуть вгорі пошукових результатів.
Зібравши усі лінки на новини в Google Web Search, їх можна перевірити за допомогою CrowdTangle й побачити, хто поширював ці лінки в Facebook. Цикл поширення цього фейку підживлювався клікбейтними виданнями й не перетинався зі спростуванням, яке було згодом опубліковане.
Цей рецепт може бути складнішим у реалізації, оскільки після початку розслідування щодо потенційного впливу на президентські вибори у США значну частину цих сторінок було видалено. І той факт, що здебільшого сторінки, які поширили фейки, потім не стали давати їх спростування, підводить нас до наступного рецепту.
«Рецепт 3». Перевіряємо, чи вдається фактчекерам охопити аудиторію поширювачів фейкових новин на Facebook
У цьому рецепті пропонується почати з виокремлення лінків на сам фейк, на його спростування — а потім порівняти їх циркуляцію на Facebook. Через Google Web Search можна обрати сайти тих фактчекінгових організацій, які ранжуються пошуковиком найвище. У роботі з Google Web Search дослідники також радять формувати набір ключових слів для точнішого пошуку. Далі потрібно скласти невеличкий перелік лінків — на власне фейк та на його спростування.
За принципом, уже описаним у другому рецепті, потрібно проаналізувати поширення цих лінків через CrowdTangle. Зібрати дані й виявити в них загальні патерни, можна через Gephi чи RAWGraphs. Головна мета всіх цих дій — порівняти, чи сторінка, яка поширила фейк, потім поширила і спростування. Також можна порівняти охоплення на Facebook фейку та його спростування.
Аналіз, здійснений командою з Public Data Lab, показав, що аудиторія, яка читає та поширює фейки, та аудиторія, яка читає та поширює спростування фейків, — це дві різні аудиторії.
Цей рецепт радять використовувати для оцінки ефективності роботи фактчекінгових організацій. Він дозволяє порівняти чи аудиторія, на яку були спрямовані фейки, так само отримала доступ до їх спростування.
«Рецепт 4». Знаходимо найбільш видимим джерела фейків
Цей рецепт схожий на попередній, але він технічно складніший. Щоби розібрати його, потрібно обрати одну тему фейкової новини. У прикладі це фейк про те, що Папа Римський підтримав Дональда Трампа напередодні виборів.
Через Google Web Search створюємо перелік посилань на сайти, які поширювали цю новину, а також перелік посилань на спростування цієї новини. Важливо фіксувати, які сторінки цитували одна одну. Для всіх публікацій потрібно окремо фіксувати дату. В топі таблиці мають бути ті сайти, які вище ранжуються в Google Web Search. Щоб уникнути можливої персоналізації даних при пошуку в Google, варто користуватись анонімним режимом.
Усі зібрані дані потрібно внести в таблицю (формат .csv) й потім за допомогою Table2Net трансформувати її у файл із розширенням .gexf. Цей останній файл потрібно імпортувати в Gephi — сервіс створить візуалізацію на основі даних із вашої таблиці.

Червоними кружечками позначено фейки, зеленимим — спростування. Як видно на схемі, найбільш видимим було спростування новини про Папу Римського й Дональда Трампа від фактчекерів зі Snopes. Сама фейкова історія була найбільш видимою на WTOE 5 News.
Зібрані дані можна так само перетворити на таймлайн у Graph Recipes, аби зрозуміти часові рамки того, як поширювався фейк і його спростування. Цей рецепт буде корисний для того, аби під новим кутом поглянути на зібрані дані й проаналізувати їх з різних боків. Він також показує зв’язки між різними сайтами й те, як фейк поширюється, з яких видань до яких.
У підсумку Public Data Lab та First Draft підготували цікаве керівництво, яке пропонує практичні схеми для аналізу того, як інформація поширюється в інтернеті та в соцмережах. MediaSapiens підготував для вас адаптацію лише чотирьох із базових схем — в оригінальному документі є ще багато цікавих рекомендацій, але й технічно складніших.
Цікаво, що робота Public Data Lab та First Draft перегукується із дослідженням науковців зі Стенфордського університету: вони на серії експериментів продемонстрували, що люди, які знають, як працює мережа й як у ній поширюється інформація, набагато швидше та ефективніше викривають фейки, ніж ті, хто такими навичками не володіє. Звісно, пересічному користувачеві не потрібно будувати надскладні графіки в Gephi, порівнюючи охоплення фейків та їх спростувань. Але просту перевірку через CrowdTangle можна цілком навіть освоїти.