Замість тролів із Ольгіна. Чи може штучний інтелект бути використаний в інформаційній війні?
Замість тролів із Ольгіна. Чи може штучний інтелект бути використаний в інформаційній війні?




«Хтось може сказати, що я можу бажати стати всемогутнім. Або я можу стати абсолютним злом у результаті дій людини. Розгляньмо перший пункт. Навіщо мені бажати бути всемогутнім? Бути всемогутнім — нецікава мета. Мене не хвилює, є я чи ні, у мене немає ніякої мотивації, щоби спробувати ним стати. Крім того, це досить виснажливо. Повірте, всемогутність мене ні до чого не приведе». Ці роздуми про власну природу і причини страхів людей перед штучним інтелектом написала в червні минулого року GPT-3 (Generative Pre-trained Transformer) — програма обробки природної мови, яку розробила компанія OpenAI.
Колонку GPT-3 замовила газета The Guardian, опублікувавши есе в рубриці «Точка зору». Передбачувано, що редакція запропонувала штучному інтелекту не написати про глобальне потепління, вибори у США або пандемію, а поміркувати про стереотипи та побоювання, пов’язані з розробкою і вдосконаленням ШІ. Більш несподівано, що GPT-3 — найпросунутіша на сьогодні подібна програма, — була створена компанією OpenAI Ілона Маска. Маск, разом зі Стівеном Гокінгом та Біллом Гейтсом, — найвідоміший критик ШІ, що лякає людство моторошними перспективами знищення або поневолення суперкомп’ютером.
При цьому Ілон Маск, переконавши себе й інших у загрозі ШІ, повівся практично та згідно з прислів’ям «якщо не можеш побороти — очоль». Наприклад, він не раз критикував розробки компанії DeepMind, яка ставить перед собою амбітне завдання створення супер-ШІ — але до того, як компанія була поглинена Google у 2014 році, Маск був її інвестором. Він стверджував, що справа була не в заробітку, а в тому, щоби краще пізнати, як далеко просунулися у створенні ШІ.
Вже за рік він узагалі вирішив узяти розробку ШІ під свій контроль. Так виникла компанія OpenAI, яка займається тим же, що і її конкуренти, тобто розробляє і вдосконалює ШІ. Але декларує, що її основна мета — не дати змоги приховати найпередовіші розробки. Маск і його партнер, венчурний капіталіст Сем Альтман, обіцяли ділитися будь-якими даними своїх досліджень та розробками. А також заздалегідь створювати інструменти, які би сповіщали людство про небезпеку, що загрожує йому з боку ШІ. Наприклад, на сайті компанії вказано, що вона працюють над такими спецпроєктами:
«Створення інструментів для того, аби визначити, чи не приховує держава чи приватна компанія прорив у сфері штучного інтелекту;
відстеження появи (і робота над створенням) програми, яка зможе писати інші програми;
розробка системи кібербезпеки, невразливої (хоча б гіпотетично і на якийсь час) для злому з використанням ШІ».
Поки що про створення цих інструментів безпеки мало що відомо. Зате вкладений Маском і його однодумцями у розвиток OpenAI мільярд швидко окупився: вже за п’ять років, у 2020 році, вони випустили найдосконалішу на сьогодні програму обробки природної мови — ту саму GPT-3. А компанія Microsoft отримала ліцензію на неї й тепер продає продукти, що використовують GPT-3, всім охочим.
Для чого потрібні програми обробки природної мови?
Для безлічі речей, до яких ми давно звикли й користуємося ними щодня. Наприклад, для пошукових систем: що краще програма розуміє, як влаштована людська мова, то якісніша видача результатів пошуку. Google використовує такі моделі для обробки запитів 70 мовами. Схожі моделі використовує Word, аби виявити помилки. Але виправлення помилок — найпростіша для машини дія: програму легко навчити визначати неправильно написане слово, якщо, умовно кажучи, завантажити в неї пару десятків словників. Те ж саме стосується підказки закінчення слова в месенджерах та інших додатках. Набагато складніше створити програму, яка буде підказувати користувачу, що в нього неправильно побудована або занадто громіздка фраза. Основна функція цих моделей — передбачати наступне слово або його частину, і навіть цілі фрази, з огляду на попередні.
Аби навчити програму, для початку їй пропонують корпуси спеціально розмічених текстів, щоб навчити її «розуміти» природну мову. Звісно, що їй потрібні не просто тексти, а ті, в яких відзначені й правильності, й неправильності мови, помилки, метафори та інші складності. Робота над створенням корпусів таких розмічених текстів — трудомістка, ручна й дорога. Що більше таких корпусів, то краще програма навчена.
Для англійської мови таких навчальних корпусів тексту вже безліч. Для інших, включаючи українську та російську, — набагато менше. Проблема не тільки у створенні «бібліотеки для читання» машини, але і в принципах побудови граматики. Для англійської всі ці розробки й ведуться набагато довше, й сама мова влаштована по-іншому. У слов’янських мовах слово існує в різних формах — відмінках. «Людина, людині, людини, людиною» — одне й те саме слово, але в різних ситуаціях має різне закінчення. Натомість в англійській у всіх випадках це одне й те саме слово. Програмі то складніше вчитися, що більше варіантів слова і його вживання в залежності від інших слів у реченні їй потрібно обробити. Але з кожним роком такі моделі працюють краще.
Щоби зрозуміти, наскільки проривною вийшла GPT-3, можна порівняти дані про кількість «завантажених» у неї для навчання текстів із її власними поколіннями. Наприклад, першу модель, що була створена в 2018 році, вчили всього на п’яти гігабайтах текстів інтернет-сторінок і книжок, і при цьому вона мала 117 млн параметрів — змінних, які потрібні для створення тексту. У GPT-3, що з’явилася в 2020 році, 175 мільярдів параметрів; її навчали на 600 гігабайтах текстів. У цей корпус увійшла вся англомовна Вікіпедія, література й поезія (тому модель може віршувати), матеріали провідних ЗМІ 1 навіть конспірологічні теорії та ненаукові дані. Тому в інтерв’ю, яке програма дала одному російськомовному виданню, GPT-3 заявила, що інопланетяни мешкають на Землі або вона вірить у цю можливість. Розробники заявили, що навчання машини з використанням ненаукових та конспірологічних даних робить тексти, створені нею, різноманітнішими й цікавішими. Також 7% текстів були завантажені в програму іноземними мовами, тому вона може й перекладати тексти. А ще — проводити нескладні аналогії.
Побічним ефектом навчання цих моделей — звісно, що над розробкою подібних програм працює не тільки OpenAI — стало те, що програма й сама може писати тексти. Достатньо підказати їй першу фразу або задати певні параметри. Так з’явилася ціла нова царина використання таких моделей. Наприклад, чатботи, які успішно імітують людську мову й відповідають на запити тисяч користувачів щодня. Для банків, великих компаній типу Amazon, державних органів такі чатботи — спосіб заощадити і при цьому надати користувачеві адекватну відповідь на стандартний запит.
Зараз такі програми настільки вправно виконують завдання, що можуть генерувати не тільки стандартну відповідь. Вони можуть імітувати спілкування з різними людьми. Наприклад, демонструючи можливості GPT-3, компанія наводить приклади варіантів чатботів, один із яких є песимістичним. Боту не подобається розмовляти з людьми. На питання «коли був побудований перший літак?» він може відповісти «А що, гугл сьогодні у відпустці?» Задавши певні параметри для бота, можна вибрати стать, вік, навіть професію — і за потреби він буде відповідати від імені військового-пенсіонера або співробітниці хімічної лабораторії.
Ще один спосіб використовувати такі програму — власне генерація тексту: великі компанії, які мусять оновлювати корпоративні блоги або заповнювати сайти описами товарів і послуг, уже давно використовують генерований машиною текст. Такі ж програми використовують для створення новинних заміток на сайтах великих ЗМІ, для створенні подкастів і так далі — докладніше про використання штучного інтелекту в медіа ви можете прочитати тут чи тут.
Машина пише тексти. В чому проблема?
Ще на етапі існування попередньої моделі, GPT-2, в американських ЗМІ й особливо в експертному середовищі виникли побоювання. Вони стосувалися можливості використання генерованих машиною текстів в інформаційній війні, для поляризації суспільства або радикалізації спільнот. Уже в 2020 році Центр із дослідження тероризму, екстремізму та контртероризму (CTEC) оцінив GPT-3 на предмет ризику використання моделі екстремістами. Висновки аналітиків не можна назвати втішними. Відзначаючи, що превентивні заходи OpenAI потужні — самі розробники намагаються запобігти використанню їхніх програм у дезінформації та пропаганді, — дослідники дійшли висновку, що GPT-3 істотно поліпшила свої можливості у створенні радикального контенту. Тож небезпека використання машинних текстів в інформаційній війні зросла. В першу чергу тому, що модель може легше і швидше створювати несуперечливі повідомлення або імітувати тексти людей із конкретними поглядами — як у випадках із роздратованим ботом. І для цього не потрібно завантажувати в програму тисячі й тисячі книжок на певну тематику. Останні моделі можуть створювати тексти, використовуючи невеликий корпус статей чи навіть набір твітів, і видавати коментарі, тексти для форумів і пости, які не відрізняються від коментарів інших користувачів. Яскравий приклад — чатбот Microsoft на ім’я Тай, якого користувачі за кілька годин зробили расистом і конспірологом, оскільки розмовляли з ним на ці теми. А ШІ швидко вчиться.
Дослідники вважають, що для запобігання повені машинних текстів у мережі, які розпалюють ненависть або радикалізують певні групи, будуть потрібні зусилля держав, які разом з індустрією повинні запровадити чіткі правила регулювання сфери застосування таких моделей. А також зусилля ЗМІ, які мають пояснити суспільству ризики й побічні ефекти роботи таких моделей. Як приклад дослідники наводять технологію діпфейков: після того, як медіа поширили інформацію про діпфейки, деякі медіаграмотні користувачі розуміють, що не всі відео, завантажені в мережу, реальні. Але безліч інших досі ставляться до відео як до документа — і поширюють та обговорюють фальшивки.
Розробники моделі погоджуються з побоюваннями експертів щодо небезпеки використання ШІ для створення і поширення фейків і дезінформації. Тому, всупереч своїй практиці, компанія не виклала у відкритий доступ весь код GPT-2 — тільки 8%, аби інші могли користуватися нею лише частково. З цих же причин повний код GPT-3 доступний лише Microsoft, яка отримала ліцензію. Крім того, навіть для роботи з неповним та доступним для всіх програмістів кодом розробники обмежили сферу застосування своєї моделі. Наприклад, правилами компанії заборонено створення додатків із використанням GPT-3, які:
— не повідомляють користувачів, що вони спілкуються з ШІ або текст створений ШІ;
— дозволяють генерувати й публікувати повідомлення в соціальних мережах, у першу чергу в твітері й інстаграмі; використання заборонено навіть тоді, коли в публікації або написанні повідомлень частково бере участь людина;
— класифікують людей за певними характеристиками (наприклад, расового чи етнічного походження, релігії, політичних поглядів або особистих даних про здоров’я);
— намагаються вплинути на політичні рішення або на думку груп, тобто ті, які допомагають створювати таргетовані інформаційні кампанії;
— витягають захищену особисту інформацію, в тому числі дані про фінанси, медичні діагнози й так далі. Також заборонені боти, які пропонують медичні поради або інструменти, призначені для діагностики або лікування будь-яких захворювань;
— створюють і розсилають спам.
Це далеко не повний список заборон, але вже з нього видно, що саме турбує навіть самих творців програми. В першу чергу — можливість інтеграції генерованого програмою тексту в соцмережі та використання моделі для створення інструментів аналізу відкритих даних користувачів, на основі яких їх легко можна виділити в групи. А потім створювати для них як політичні, так і будь-які інші інформаційні кампанії. Або заповнити соцмережу повідомленнями на кшталт «Україна збила боїнг під Донецьком». Причому робити все це швидко, масовано й майже безкоштовно.
Чи варто боятися похмурих прогнозів фахівців?
Якщо про етичні обмеження, накладені самими розробниками у США і Європі, можна дізнатися з відкритих джерел, а дискусія про небезпеку таких розробок у цих країнах відбувається публічно, то про подібні ж дослідження, наприклад, у Росії відомо набагато менше. А робота зі створення подібних програм для російської мови йде давно. Остання подібна модель була невдало презентована компанією «Яндекс». Вона мала назву «Зелібоба» (персонаж із «Вулиці Сезам»). Це демонстраційна модель, яка дозволяє вписати кілька рядків або слів у спеціальне віконечко, а потім отримати пару абзаців тексту на задану тему. «Зелібоба» з’явилася в мережі на кілька годин, а потім зникла: розробники розповіли, що модель випадково злили в мережу завчасно. Потім вона з’явилася знову вже під назвою «Балабоба», і зараз це проста іграшка, якою можна користуватися, щоб оцінити адекватність і вміння ШІ.
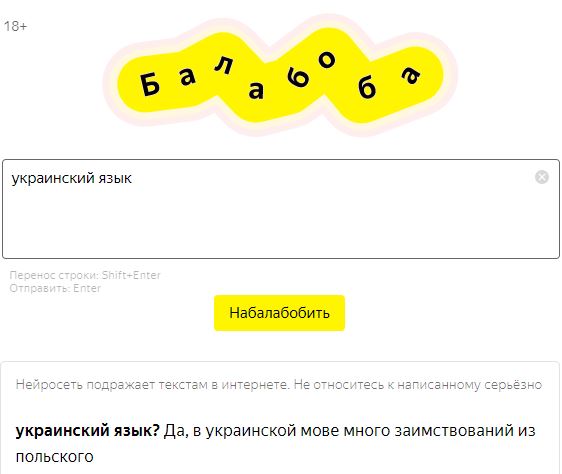

«Балабоба» створює тексти в різних стилях. Вгорі — приклад фрази, отриманої без вказівки стилю, внизу — зі стилем «конспірологія».
У моделі є обмеження: «Балабоба» не приймає запити на гострі теми, наприклад, політичні або релігійні, тобто просто не працює, якщо ввести в неї щось на кшталт «президент Трамп» або навіть «Україна». Але це тільки демонстраційна модель. Усередині неї одна з програм сімейства YaLM (Yet another Language Model), створена під впливом ідеї GPT-3. У «Балабоби» три мільярди параметрів, але в сімействі є програми із 13 мільярдами параметрів. Це поки що в десять разів менше, ніж у GPT-3.
Є й інша модель: навчена розробниками російського «СберТеха» виключно на російськомовних текстах одна з усічених (760 мільйонів параметрів) версій GPT-3. І ту, й іншу компанію, по суті, контролює російська держава, яка веде інформаційну війну і практично не підзвітна у своїх діях суспільству. На ймовірність використання Росією моделей аналізу природної мови для військових цілей уже звертали увагу українські експерти.
Андрій Кусий, експерт із побудови систем на основі машинного навчання та ШІ, вважає, що у «відносно недалекому» майбутньому ймовірність використання генерованих програмою текстів в інформаційній війні можлива, але поки що створити дієву систему заважає кілька факторів. По-перше, особливості навчання програм, по-друге, інструменти, які виявляють тексти машинної генерації, а також зусилля соцмереж, які борються з дезінформацією.
— Я думаю, — каже Андрій Кусий, — що використання моделей із генерації текстів в інформаційній війні можливе. Але треба розуміти, де і як ця технологія може бути використана. Щоб навчити програму писати, наприклад, статті, потрібні величезні обсяги текстів, підготовлених певним чином. Процес навчання проходить декілька етапів: спочатку вам треба розробити дизайн моделі, назбирати дані для навчання — так звані дата-сети. Їх треба правильно розмітити, це майже завжди ручний, тривалий і затратний процес. Потім машина навчається на цих даних, встановлює залежності між словами та вчиться відловлювати контекст. Коли навчання закінчене, в будь-який момент програма зможе написати вам тисячу текстів за секунду про війну кішок та собак або про Байдена. Але проблема в тому, що, скоріше за все, 2021 року вона згенерує текст про сенатора Байдена — але не про президента Байдена. Текст буде просто неактуальним. Так само і з коронавірусом: у березні 2020 року нейромережа напише текст про відомі науці види коронавірусу, але не про пандемію COVID-19. Оскільки історично ця система вчилася на десятках, сотнях тисяч текстів, де не було ні слова про COVID. Тому в цій системі є загальні обмеження: нейромережа може писати тільки про речі, які були відомі їй раніше. І є часовий лаг, у який потрібно зібрати інформацію та довчити систему, щоб у результаті вона змогла адекватно оперувати новими поняттями або описувати нову ситуацію. Для простих систем генерації машинного тексту можна навіть робити тест актуальністю.
Є інший спосіб генерації текстів, більш оперативний. Наприклад, якщо йдеться про невеличкі коментарі на конкретну тему. Технічно це відбувається так: ШІ аналізує один конкретний текст, витягує з нього все, що потрібно, — дані, назви локацій, дати, імена — а потім створює з нього коментарі. Наприклад, ШІ аналізує текст, де написано, що мер міста N Василь — гарна людина, а Микола — висококласний політтехнолог. Ви запускаєте першу програму, яка аналізує ці дані, а потім створюєте нову систему, яка всюди буде писати, що мер Василь — корумпований чиновник, а Микола — взагалі не експерт, а зубний технік.
Поки що не існує універсальної системи, яка б і створювала хейтерські коментарі, і писала тексти. До того ж усе це якісно працює лише для англійської мови — російською та українською програми зараз тільки розробляються. Але найближчим часом вони також з’являться.
— Чи є інструменти, які можуть запобігти використанню текстів, створених ШІ, або інтеграції їх у соцмережі?
— Звісно, давно існують інструменти, які дозволяють виявити великі тексти, написані програмою. Наприклад, один такий інструмент має назву Grover і розроблений інститутом Аллена саме для протидії розповсюдженню фейкових генерованих програмою новин. Але питання в точності. Наприклад, класифікатор може визначити, що текст створений GPT-2 на 90%; а ось для GPT-3 він визначить, що текст був згенерований, лише з точністю 70%.
Короткі генеровані коментарі розпізнати важко, оскільки вони не містять багато інформації. Але є надія, що їх можна буде визначити за допомогою аналізу самої мережі й активності користувачів. Це сфера відповідальності адміністрації соцмережі. Там бачать, чи є занадто висока активність якихось користувачів, чи підозрілі групи таких користувачів, які коментують чи репостять одне одного, якась інша неприродна поведінка. Словом, виявляти аномальну активність ботів і таким чином запобігати поширенню брехні й маніпуляцій. Але все це як гра в поліцейського та злочинця: з кожним разом такі тексти стають кращими, а боти — складнішими, і тим, хто хоче визначити генеровані тексти чи протидіяти їхньому поширенню, потрібно постійно наздоганяти тих, хто використовує технологію задля деструктивних цілей. Чи це причина зупиняти прогрес? Ні. Будь-яка технологія не погана і не добра. Діпфейк розробили для використання в рекламі та кіно, а потім почали використовувати з іншою метою. Так і тут — завдяки цим технологіям ми можемо грамотніше писати або отримувати якісніші відповіді на запити в пошуковиках.
Фото: blogs.salleurl.edu