Nvidia представила нейромережу, що створює відео за текстовим описом
Nvidia представила нейромережу, що створює відео за текстовим описом




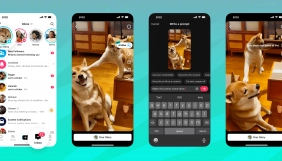
Дослідницька компанія Nvidia розробила нейромережу під назвою VideoLDM, яка генерує відео за текстовим запитом користувачів.
Генератор відео використовує Stable Diffusion і наразі може синтезувати короткі ролики тривалістю до 4,7 секунди. Нейромережа генерує відео з роздільною здатністю до 1280×2048 пікселів з частотою 24 кадри за секунду і враховує близько 4,1 млрд параметрів.
Для цієї технології розробники застосовують Latent Diffusion Models (LDM). Такий підхід дає змогу синтезувати високоякісні зображення і не витрачати багато обчислювальних потужностей, адже модель тренується у стиснутому низьковимірному латентному просторі.
«Спочатку ми тренуємо LDM виключно на зображеннях, а потім перетворюємо генератор зображень на відеогенератор: додаємо часовий вимір до LDM-моделі та точно налаштовуємо послідовність закодованих зображень, тобто відео», — пояснили розробники.
Детальніше ця технологія описана на сайті Nvivdia, де компанія показала приклади згенерованих за текстовими описами відео. Серед них — «Вдягнена в костюм лисиця, що танцює в парку», «Самотній мандрівник у туманному лісі на світанку», «Снігова людина у заметілі» та багато інших.
Наразі це лише дослідницька розробка. Поки що компанія не викладає інструмент у відкритий доступ.
Нагадаємо, на початку 2023 року компанія Nvidia додала до програми Nvidia Broadcast 1.4 нову функцію «Зоровий контакт», створену за допомогою «штучного інтелекту». Опція імітує погляд людини в камеру, навіть якщо в реальному житті вона дивиться в інший бік. За інформацією розробників, функція призначена для «творців контенту, які прагнуть записати себе під час читання своїх нотаток або сценарію», коли не дивляться прямо в камеру.
Фото: Nvidia